Please introduce yourself. What’s your name, your background and your current role at Imperial Brands?
Hi, my name is Thomas Verron. My background is mainly science and mathematics. I have a PhD in Biostatistics and an MBA in Big Data. I’m based in France and lead the Computational Science function at Imperial Brands. I’ve worked here for 16 years, am passionate about machine learning and enjoy using R or Python programming languages to solve practical problems within the business.
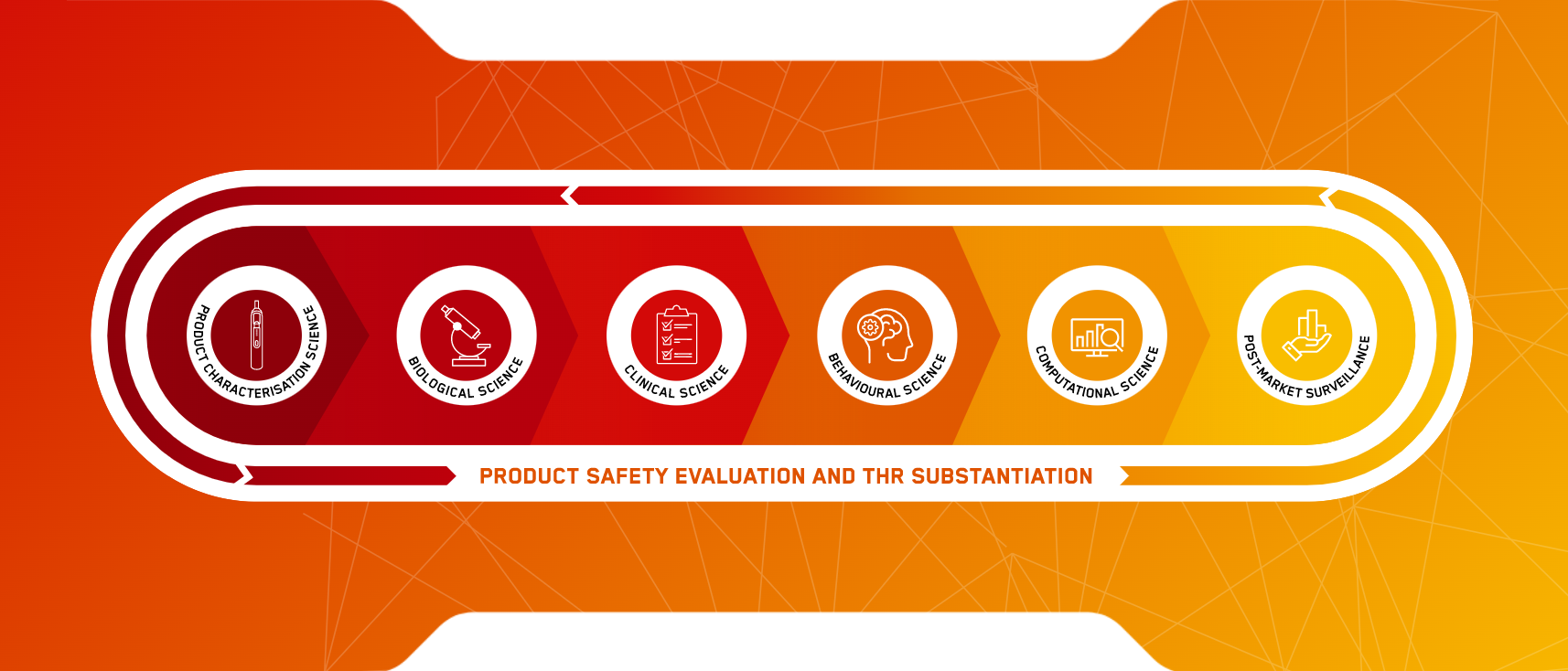
Why is computational science an important part of the Scientific Assessment Framework (SAF)?
We closely work with the various departments in the Harm Reduction & Engagement team in Group Science & Regulatory Affairs (GRSA), helping them to extract data from their research to demonstrate how our next generation products (NGP) can potentially help make a meaningful contribution to tobacco harm reduction (THR).
Computational Science is a sprawling topic and involves diverse elements like machine learning, datamining, deep learning and data analysis. With these powerful tools, we solve complex problems and support the outputs of the SAF.
Can you provide a little more detail around some of the areas you just mentioned?
Machine learning algorithms are designed to learn from both input and output data, and make predictions or decisions without being explicitly programmed to do so.
Deep learning is a subfield of machine learning inspired by brain architecture that demonstrates high capability for image detection, object identification or text analysis. It’s widely used in artificial intelligence; for instance, the highly advanced chatbot Chat-GPT which is currently a very popular topic in the news.
So how is big data helping Imperial make a meaningful contribution to THR?
Imperial NGP science generates a massive variety of datasets (e.g. chemical, social network, physical, biological, clinical, behavioural…!) So, we need to use big data technology to ingest, cleanse, structure and model these data to extract the pertinent scientific evidence to demonstrate our NGP are potentially helping contribute to THR.
Can you provide a couple of specific examples?
Sure. Our virtual Data Science Lab (DSL), for instance, is very adept at processing pharmacokinetic data. It helps our scientists to structure and model them in ways that help predict the absorption, distribution, metabolism and excretion of nicotine in the body.
Then, we use cloud computation to develop simulations bridging the results for every variant of said product (for example, different flavours or nicotine strengths).
The idea is to harness these new technologies to limit the number of physical studies, and instead use the power of cloud computing to model the results to each NGP variant.
Amazing! How about population modelling?
We use population modelling to predict the long-term (i.e. decades) impact in terms of prevalence and consumer health of the introduction of an NGP on a specific market. The predictions are based on mathematical models and our knowledge of consumers in terms of product initiation, switch, relapse or cessation.
This technique allows us to model realistic public health scenarios that are – for many reasons – impossible to conduct in the real world; for example, using NGP that have not yet been launched in markets. One usage of these outputs could be, for instance, to assist in our engagement to regulators around the public health potential of NGP.
Tell us more…
Our dynamic model is a hybrid between a population-based model and an individual-based one. It means we can simulate the route of every individual in term of product consumption, and any ensuing impact on health and/or mortality.
For instance, we modelled the US market based on the supposition that vaping can potentially reduce smoking-related mortality by 95%. Our model predicted that, 60 years following the category’s introduction, more than a million premature deaths could potentially be averted if certain numbers of adult smokers switched to vaping.
We’re currently working on some enhancements to our model. For instance:
How does our data modelling fit into the wider SAF?
We use data modelling to identify trends and patterns in the data, but also to predict future outcomes or to help optimise existing processes.
For instance, we recently worked with the Product Characterisation team to help them develop an application to validate product changes by performing product comparisons based on critical differences.
The interactions between our data modelling and product characterisation expertise opened new perspectives and ideas on how we can use and compare data, which was a very satisfying and rewarding project to be involved in.
You mentioned the DSL earlier. Can you tell us a bit more about it?
Of course. We proposed and created the Data Science Lab to both improve the governance of data in GSRA, help facilitate data mesh and lineage and fulfil the business’s growing demand for advanced analytics. Through the DSL, our science colleagues are beginning to uncover hidden trends, patterns, and opportunities in their data – which is fantastic!
Any other initiatives you’d like to share?
We recently collaborated with the Product Standards team to help them to develop automated regulatory reporting. The objective is to generate reports automatically, without the need for manual intervention.
Advantages include saving time, improve the accuracy of our reporting and increasing the efficiency of the team. Better governance of regulatory data will open up exciting new possibilities by providing far faster access to large amounts of more relevant data in the future.
What are the most interesting or exciting elements about your team’s role in the business?
I would say our ability to use our knowledge and expertise to find innovative, technological and data-driven solutions to complex problems.
We’re constantly looking for unique ways to make data and technology work harder for Imperial, creating new models, apps and visualisations for our harm reduction science experts.
What are the biggest challenges in your role?
One of the biggest challenges is staying up-to-date with constant advancements in technology.
Technologies like machine learning and artificial intelligence are evolving and changing with each passing day, so it can be challenging to keep track of new developments – let alone integrate them into business processes!
In addition, I need to collaborate effectively with others to create genuine value-add. This includes working with subject matter experts inside the business, but also with data scientists outside of Imperial to ensure the results of our models are meaningful and actionable.
Another challenge is the ability to collect the right data. It’s the foundation of any science project, and collecting high-quality, relevant data is critical for improving our models and producing realistic results which help drive our THR research and engagement.
What’s it like working in Imperial’s science function?
I find it very rewarding! I collaborate with scientists and engineers from around the world on innovative projects to support our NGP ambitions. I also believe there’s great potential for career growth and development within Imperial’s science function.
Would you recommend IMB as a place to work?
Definitely. Imperial Brands is a great place to work with a dynamic and forward-thinking culture that encourages employees to be creative, think outside the box, and make an impact.
You are free to share this content with credit to Imperial Brands under a Creative Commons Attribution-NoDerivatives 4.0 International (CC BY-ND 4.0) license.